 架构与功能
架构与功能
# 系统架构及概念
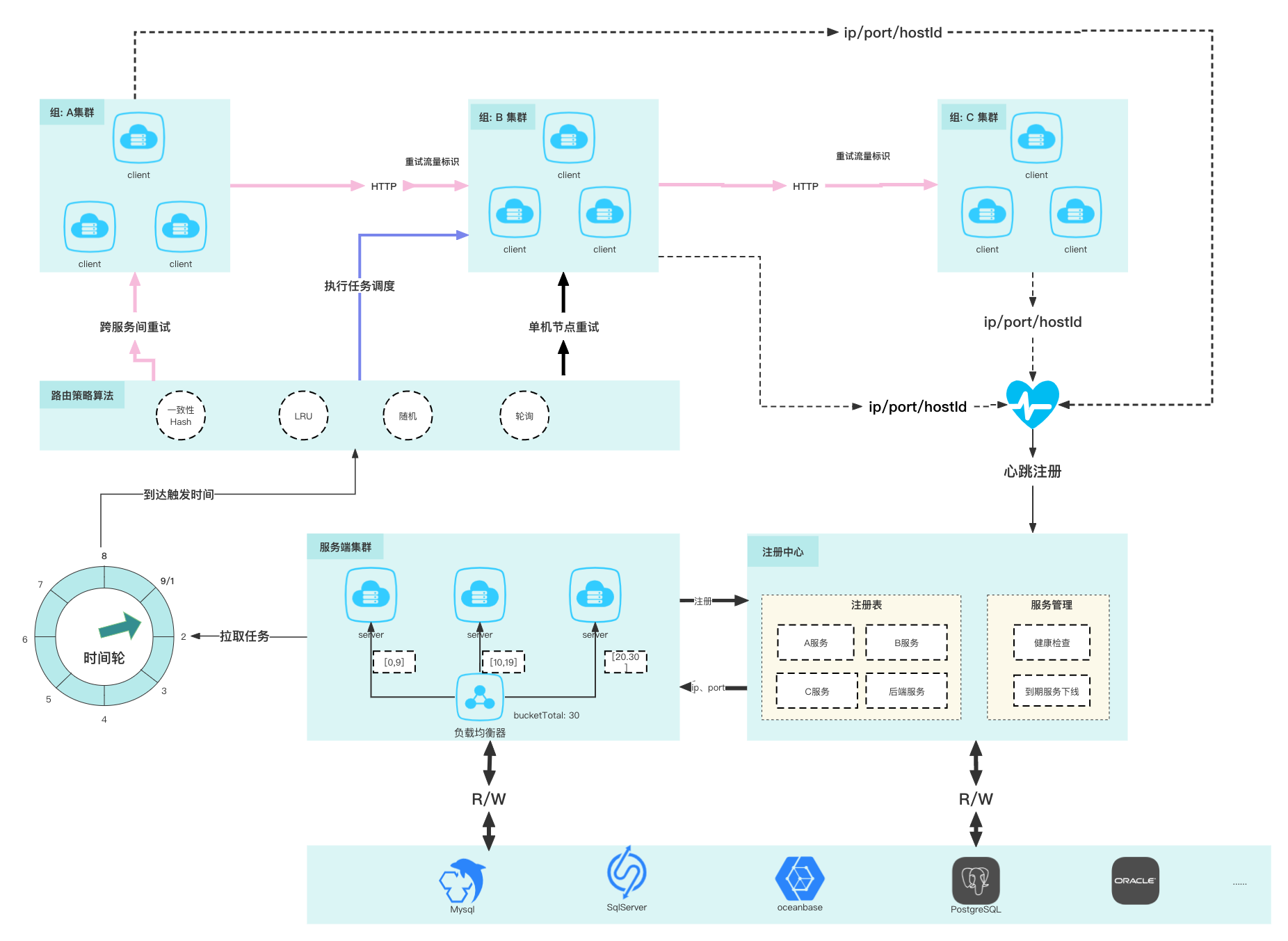
# 客户端
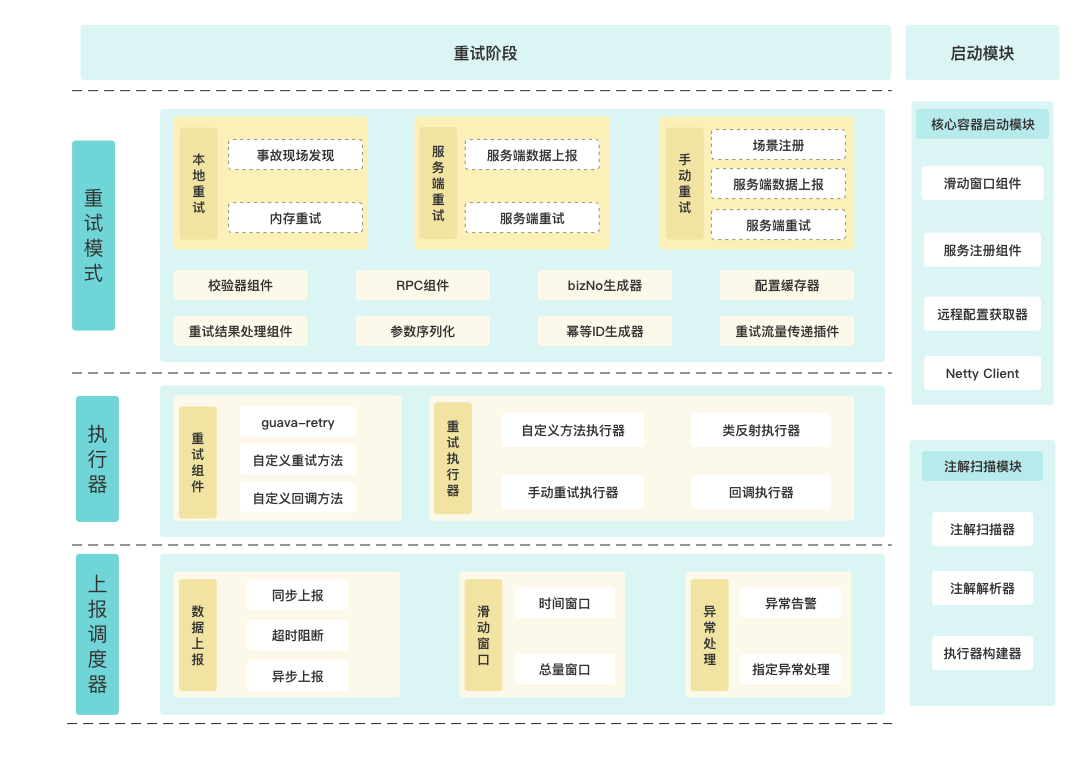
# 校验器组件
在重试过程中,EasyRetry会对重试流量做出标识。在后续的重试过程中,EasyRetry将会做出以下限制:
- 重试流量不开启重试
- 重试任务进行中的流量不进行重试
- 下游响应不允许重试状态码,不开启重试
- 异常信息不匹配的流量不进行重试
# RPC组件
EasyRetry提供了Hessian和Jackson两种序列化方式,默认采用Jackson实现。
# bizNo生成器
bizNo是提供给用户自定义的业务唯一编号,方便用户在EasyRetry控制台进行检索,最大为64位长度的字符串。 标识具有业务特点的值, 比如订单号、物流编号等业务中的唯一key,可以根据具体的业务场景生成,生成规则采用通用成熟的Spel表达式进行解析。 @Retryable注解中通过设定参数bizNo即可完成业务唯一编号的设定。
# 重试结果处理器
在服务端重试流程中,用户可以自定义重试结束后的业务流程。例如重试成功后通知,重试失败达最大次数后回滚业务等。 EasyRetry提供了doSuccessCallback(重试成功后的回调方法)和doMaxRetryCallback(重试失败后的回调方法)两种方法。 @Retryable注解中指定retryCompleteCallback参数,实现RetryCompleteCallback接口即可实现重试结果处理器。
# 自定义方法执行器
在重试请求时,默认走原方法发起重试。但是在一些特定场景中,用户需要自定义重试的方法执行器,例如重试时检测token是否过期等。 EasyRetry提供了ExecutorMethod接口交由用户自定义设置重试方法。 @Retryable注解中指定retryMethod参数,实现ExecutorMethod接口即可实现重试结果处理器。
# 幂等ID生成器
幂等ID是指重试过程中唯一标识一次请求的ID,旨在保障相同场景、相同参数的情况下只有一次请求发出。 EasyRetry默认采用场景、类名、方法名、参数取Md5的方式来计算幂等ID,用户可根据场景需求自定义幂等ID的生成。 @Retryable注解中指定idempotentId参数,实现IdempotentIdGenerate接口即可实现重试结果处理器。
# 批量上报调度器
EasyRetry设置了同步上传和异步上传两种数据上报方式。同步上传会实时上报重试数据,异步上传则通过滑动窗口的方式来上传数据。系统默认采用异步上报的方法。 @Retryable注解中指定async=false可以开启同步上报,通过指定timeout可以设定同步上报的超时时间,指定unit可设置同步上报的超时时间单位。
# 服务端
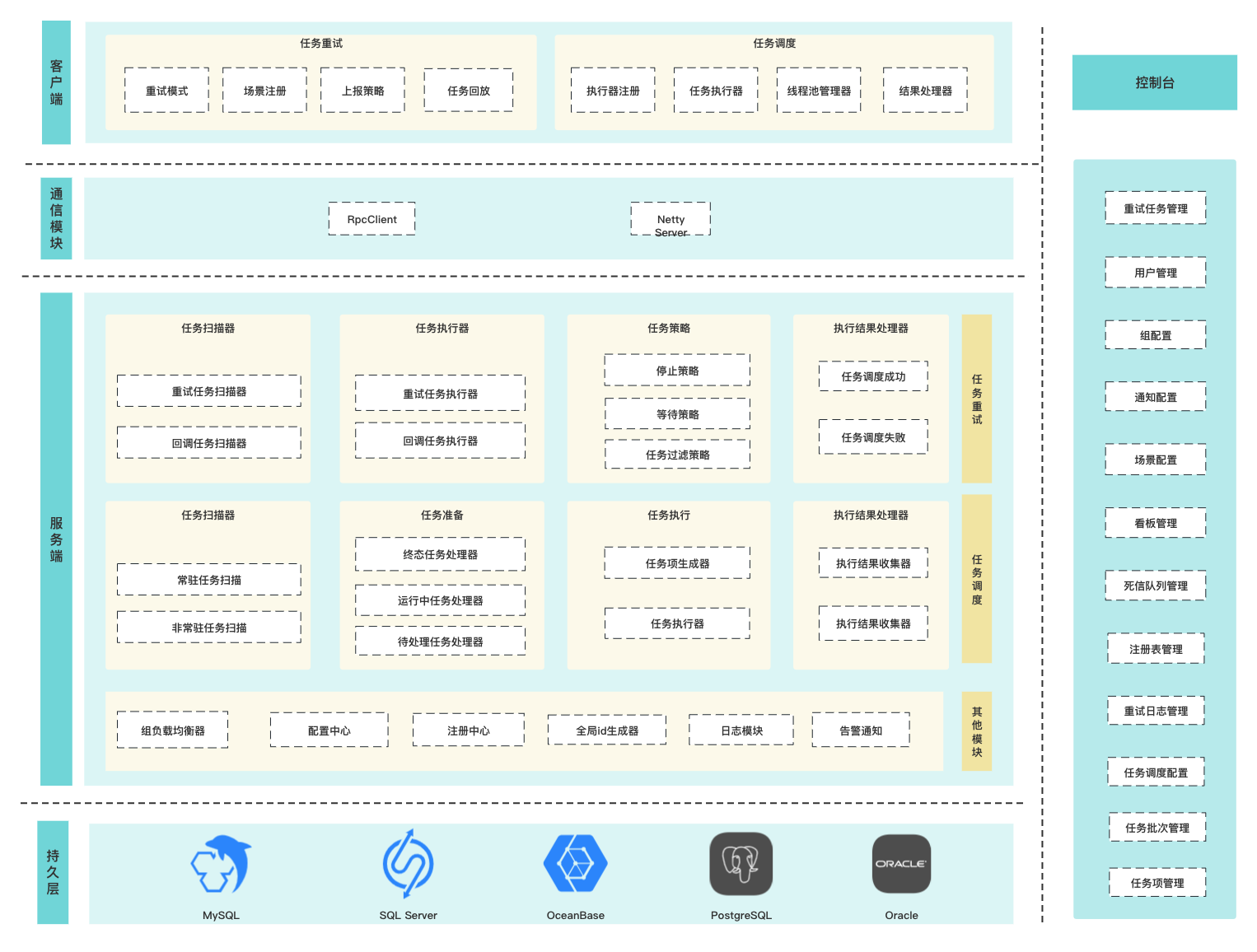
# 任务调度
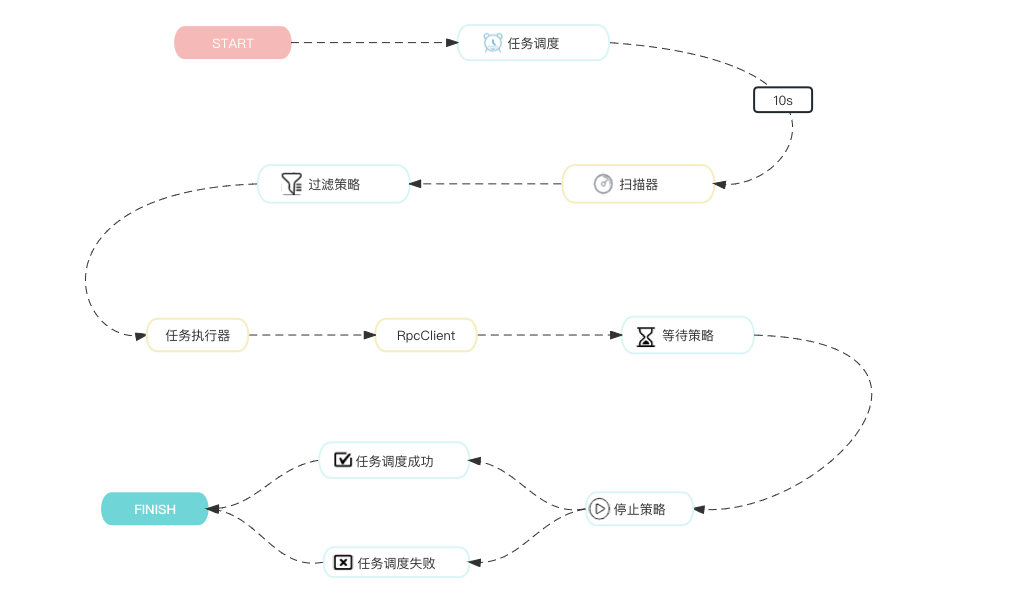
Akka 是一个用于构建高并发、分布式和弹性系统的开源工具包和运行时环境。它是基于 Actor 模型的框架,提供了一种并发编程模型,可以轻松地处理并发任务和消息传递 任务调度整体是基于AKKA实现全异步化流程
下面是整个任务调度的数据和核心节点的流转图
# 任务扫描器(ScanGroupActor,ScanCallbackGroupActor)
系统为每个组创建一个ScanGroupActor的扫描器并缓存到CacheGroupScanActor中,定时任务每10秒触发一次扫描任务,从CacheGroupScanActor通过groupName获取ScanGroupActor扫描所有任务。
扫描结果通过FilterStrategy进行数据过滤同时为了避免任务重复执行,系统采用BitSet来进行幂等标记。最终只有符合执行条件的任务会通过AKKA的发布订阅模型发送消息。
# 任务执行器(ExecUnitActor、ExecCallbackUnitActor)
- 任务执行器监听扫描器发送的消息,通过
RpcClient向客户端回放重试流量或者执行回调; - 通过控制台配置的退避策略执行
waitStrategy计算下次执行时间, 若符合stopStrategy则执行具体的停止策略 - 同时需要记录任务的执行情况(成功或者失败)
- 删除幂等标记
- 记录日志信息
# 任务策略
任务策略由过滤器策略、停止策略、等待策略组成采用责任链模式,按照
order从小到大依次执行策略
# 【过滤器策略】FilterStrategies
过滤不符合执行条件的任务, 比如未到达触发时间、无活跃的客户端等
- TriggerAtFilterStrategies: 触发时间过滤策略
- BitSetIdempotentFilterStrategies: BitSet幂等过滤策略
- SceneBlackFilterStrategies: 场景黑名单策略
- CheckAliveClientPodFilterStrategies: 存活的客户端过滤策略
- RateLimiterFilterStrategies: 客户端限流过滤策略
- ReBalanceFilterStrategies: 正在rebalance时不允许下发重试流量过滤策略
# 【停止策略】StopStrategies
判断任务是否需要终止,比如客户端返回SUCCESS或者STOP则需要停止重试、调用客户端发生异常则继续执行任务
- ResultStatusStopStrategy: 调用客户端发生异常触发停止策略
- ResultStatusCodeStopStrategy: 根据客户端返回状态判断是否终止重试
- ExceptionStopStrategy: 根据客户端返回结果对象的状态码判断是否终止重试
# 【等待策略】WaitStrategies
DelayLevelWaitStrategy是参考RocketMQ的messageDelayLevel = "1s 5s 10s 30s 1m 2m 3m 4m 5m 6m 7m 8m 9m 10m 20m 30m 1h 2h";设计 相较于messageDelayLevelDelayLevelWaitStrategy支持更多的执行次数和更长的执行时间(see:DelayLevelEnum)
- DelayLevelWaitStrategy: 延迟等级等待策略
- FixedWaitStrategy: 固定定时间等待策略
- CronWaitStrategy: cron等待策略
- RandomWaitStrategy: 随机等待策略
- 待扩展......
# 执行结果处理器
# 任务调度成功(FinishActor)
FinishActor监听任务完成消息,
- 若是重试任务完成需要创建一个回调任务,更新任务状态为已完成
- 若是回调任务直接更新任务为已完成
# 任务调度失败(FailureActor)
FailureActor监听任务执行失败消息
- 若是重试任务到达最大重试次数,则更新任务状态为最大次数并创建一个回调任务
- 若是回调任务到达最大重试次数,则更新任务状态为最大次数
# 其他模块
# 组负载均衡器
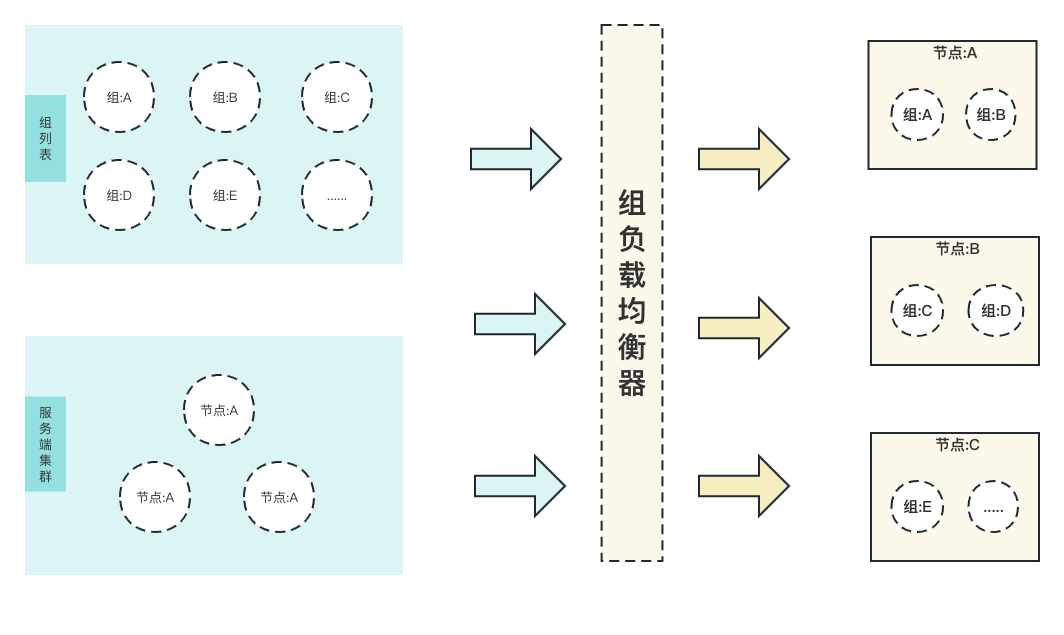
组负载均衡器通过一致性HASH算法将组均匀的分配到每个服务端节点上
以下是触发组负载均衡器ReBalance的条件
- 若本地缓存节点为空则触发ReBalance
- 若远程的节点与本地缓存节点数量不一致则触发ReBalance
- 若远程的节点与本地缓存节点hostId不匹配则触发ReBalance
- 若组远程的组数量与本地缓存的组数量不一致则触发触发ReBalance
# 配置中心
# 配置管理
通过控制台进行组、场景、通知配置, 其中组不支持默认初始化,接入时需手动新增组配置
- 组名称: 名称是数字、字母、下划线组合,最长64个字符长度
- 状态: 开启/关闭, 通过状态开启或关闭组状态
- 路由策略: 随机算法、一致性hash算法、最近最久未使用算法
- 描述: 对组进行描述
- 指定分区: 不指定则系统随机分区,指定则使用指定的分区(若系统没创建对应的表则会保存失败)
- Id生成模式: 支持雪花算法和号段模式
- 初始化场景: 【是】: 当未查询到场景时默认生成一个场景(退避策略: 等级策略, 最大重试次数: 21); 【否】: 新增场景时必须先配置场景
# 配置通知
推、拉结合的模式保障配置变更时,能及时通知客户端
-【推】服务端主动感知版本变更: 控制台变更配置时版本号会自增,此次会以轮询的方式通知客户端配置变更 -【拉】客户端主动同步配置: 客户端每次请求服务端都会携带版本号与服务端校验版本是否一致,若不一致则返回最新版本
# 注册中心
# 注册阶段
- 心跳注册: 客户端使用Netty的心跳(30s一次)与服务端保持连接,每次心跳都会将任务放到本地队列中有定时任务获取队列信息更新过期时间
- 定时任务注册: 服务端使用定时(30s一次)任务定时注册
# 过期下线
- 定时扫描到达过期时间的客户端、服务端节点
- 删除到期的客户端、服务端节点
# 全局id生成器
号段模式: 采用业界成熟的美团开源的分布式ID生成器(leaf) (opens new window)的号段模式
雪花算法: 使用hutool自带的雪花算法生成id,若出现时间回拨问题则直接报错
# 日志模块
日志分为retry_task_log和retry_task_log_message表
retry_task_log表主要是存放任务的主要信息包括 unique_id、group_name、scene_name、idempotent_id、retry_status等retry_task_log_message表存放每次调度产生的结果信息
# 告警通知
目前已支持钉钉通知、邮箱通知、飞书通知
# 通知场景:
- 重试数量超过阈值: 作用于服务端,重试中的数量到达阈值发送通知
- 重试失败数量超过阈值: 作用于服务端,达到最大重试次数的数量到达阈值发送通知
- 客户端上报失败: 作用于客户端,上报数据失败 发送 通知
# 通信模块
# RpcClint
RpcClint是通过动态代理实现的可以基于配置的路由策略选取可执行的客户端IP+PORT, 并支持路由剔除和路由转移功能
# 客户端路由策略算法
- 一致性Hash算法
- LRU算法
- 随机算法
# 路由剔除:
当调用客户端时出现网络异常时,自动剔除当前活跃列表中的下线的路由信息(IP+PORT), 并通过路由转移功能选取一个活跃的节点,从而提高了调用的可达性
# 路由转移:
重新在缓存的活跃列表中选取一个路由信息
# NettyServer
接收的客户端请求,并通过策略模式执行具体的操作
- BeatHttpRequestHandler(/beat)
- 接收心跳请求
- 将客户端携带的版本号信息存储到版本同步处理器的本地队列
- 检查版本是否一致,若不一致则向客户端推送最新配置
- 客户端缓存最新配置
- ConfigHttpRequestHandler(/config)
- 客户端启动的时候,主动拉取最新配置
- 客户端缓存最新配置
- ReportRetryInfoHttpRequestHandler(/batch/report)
- 接受客户端上报的信息
- 判断组是否存在,不存在则抛出异常
failed to report data, no group configuration found. - 场景检查
- 若初始化场景配置为【是】,则不存在场景时则自动生成一个退避策略为延迟等级、最大重试次数为21的场景配置
- 若初始化场景配置为【否】,则不存在场景时则抛出异常
failed to report data, no scene configuration found.
- 幂等检查
- 若存在幂等号、组、场景相等且是重试中的数据,则直接返回上报成功
- 生成触发时间
- 通过随机等待策略【
RandomWaitStrategy】的生成一个60秒内的随时时间
- 通过随机等待策略【
- 创建任务
- 初始化日志信息